La data science au service de l’information voyageur
Cet ambitieux projet a pour objectif d’améliorer, grâce à la data, la fiabilité de l’information voyageur et des itinéraires proposés en temps réel aux usagers. Il devrait être intégré sous peu à l’application SNCF.
Publié le
Par La Redaction

Le projet « Prévisions Retards » s’inscrit dans le cadre du programme Mobility As A Service (MaaS). Il a pour objectif de prédire quotidiennement les retards à venir sur les sept jours suivants, au départ et à l’arrivée de chaque gare Transilien. Un retard est comptabilisé à partir de 2 minutes et 30 secondes.
L’enjeu du projet est d’améliorer la fiabilité de l’information voyageurs sur l’application SNCF, via le Calculateur Multimodal d’Itinéraire (CMI), qui intègre ces prédictions de retards dans le choix des itinéraires proposés aux clients.
Ce projet a été développé par une équipe de Data Scientists et Data Engineers de l’équipe Data IoT Itnovem (e.SNCF), en étroite collaboration avec le responsable métier. Plusieurs algorithmes d’Intelligence Artificielle (IA) sont utilisés pour prédire les retards avec la plus grande fiabilité possible. Explications.
Feature Engineering, ou la préparation des données
Les données utilisées par « Prévisions Retards » sont celles des horaires théoriques et réels des trains Transilien, sur une période historique de trois ans. L’écart potentiel qui les sépare permettra de calculer le retard à chaque gare du réseau francilien. Les données sont ensuite nettoyées et transformées, afin de créer des “features”, intégrées au modèle d’apprentissage de l’outil (Machine Learning).
1. Les features calendrier :
La phase exploratoire a révélé l’impact significatif du calendrier sur les caractéristiques de retard des trains : jour de la semaine, mois de l’année, jours fériés et vacances scolaires.
Chaque instant de passage d’un train est tranché, pour être associé à une tranche horaire spécifique. Après observation de la fréquence de dessertes des trains et l’évolution typique du retard avec le temps, l’intervalle des tranches a été fixé à 15 min.
2. Les features réseau :
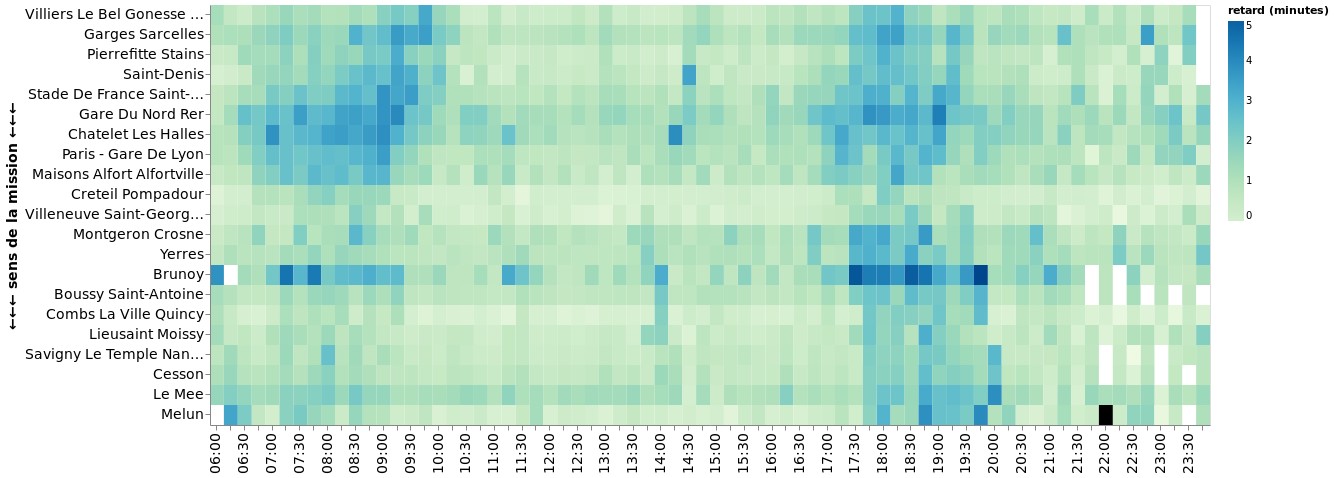
La phase d’exploration des données a également révélé que chaque ligne de train, voire chaque gare, présente un comportement spécifique et donc un retard qui lui est propre. Afin que le modèle réussisse à caractériser les gares, nous avons intégré le nombre de correspondances entre les lignes (réseau SNCF et également RATP), pour chaque gare.
Il a été également décidé de passer de la représentation gare par gare à une représentation en paire des gares, dite Origine – Destination (OD) : l’origine (O) est la gare de desserte du train, et la destination (D) est la prochaine gare desservie.
3. La météo :
Le retard est également corrélé aux conditions météorologiques. Nous utilisons donc les prévisions de Météo France, reçues quotidiennement sur notre plateforme Big Data, pour prédire le retard sur les sept prochains jours de façon plus précise. Le référentiel des stations météo et des gares franciliennes est créé par l’algorithme KNN (k-nearest neighbours), qui permet d’associer la météo d’une gare avec la mesure météo la plus proche.
4. Les features statistiques temporelles :
Pour prédire le retard d’un train de la façon la plus fiable possible, nous calculons un ensemble de statistiques sur le retard passé. Nous effectuons donc un calcul sur des fenêtres temporelles, afin de capturer le comportement du retard sur différents horizons de temps (à l’échelle du jour, de la semaine, et jusqu’aux trois derniers mois écoulés).
Cette méthode est inspirée d’une approche séries temporelles (SARIMA). Mais du fait d’un temps de traitement élevé, et de la difficulté d’interprétation des résultats, nous avons mis de côté cette méthode, pour implémenter un traitement ad-hoc.
Grâce à ce traitement, les statistiques obtenues sont optimisées afin de pouvoir capturer des “patterns” (motifs) de retards différents selon les lignes, les gares, les périodes de week-end, de vacances, etc. Ils alimenteront le modèle d’apprentissage.
Modélisation
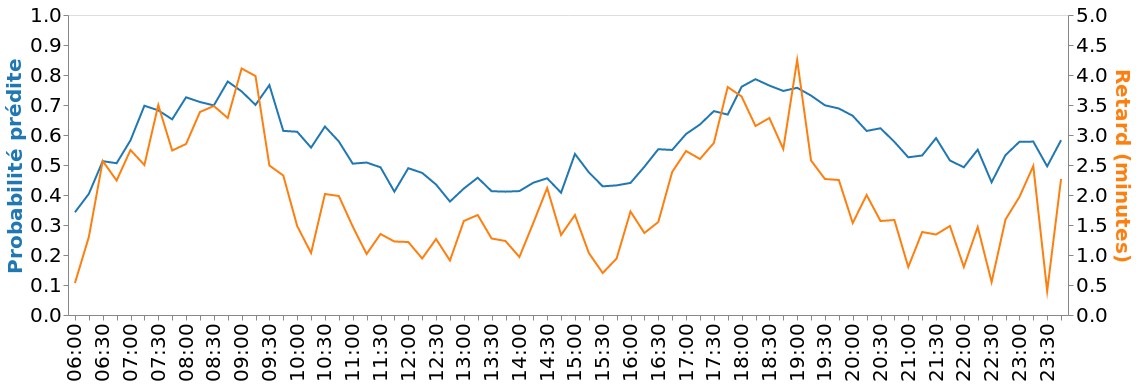
Afin de rendre le projet opérationnel et de l’industrialiser le plus rapidement possible, et en vue de la grande variabilité du retard qui rend sa prédiction exacte difficile, nous avons décidé de réaliser une classification binaire des retards.
Division de la donnée en data sets
En nous inspirant des recommandations du livre Machine Learning Yearning de Andrew Ng, nous avons construit des ensembles de tests, pour évaluer les performances de notre modèle. Afin d’éviter toute corrélation entre jeu d’entraînement et jeux de tests, nous avons créé ces derniers en isolant des journées entières dites “relativement normales”, parmi les derniers mois de circulation des trains. Le choix de ces journées est reconduit régulièrement, pour conserver des jeux de tests récents et représentatifs de l’état actuel du réseau, et des retards.
Choix du modèle
Plusieurs approches ont été testées : bagging, approche multi classe, séries temporelles. Notre choix s’est finalement porté sur une classification binaire, avec le désormais très célèbre algorithme XGBoost framework de Gradient Boosting, très performant à la fois en temps de calcul et dans ses prédictions.
Malgré le fait que chaque ligne Transilien ait un comportement de retard spécifique, l’approche adoptée est la construction d’un modèle unique, pour simplifier sa supervision (monitoring) et faciliter l’entraînement automatique. En effet, il est plus facile et moins coûteux de lancer un seul entraînement, et non plusieurs. La construction d’un modèle unique vise également à pouvoir pondérer XGBoost, et remédier au problème de classes déséquilibrées. Effectivement, un poids plus important est donné aux cas de retard (classe minoritaire) pour forcer l’apprentissage. Une pondération personnalisée des classes par ligne permet de construire un modèle unique performant sur toutes les lignes : celles avec beaucoup de retard, et celles toujours à l’heure.
Le retard a tendance à être accumulé en gare, et rattrapé pendant les trajets. Ainsi, le retard d’un train à l’arrivée en gare peut être très différent de son retard au départ de la même gare. C’est pourquoi nous réalisons une double prévision (deux modèles à entraîner) : retard des trains au départ et retard des trains à l’arrivée.
Industrialisation
En production, nous lançons l’entraînement des deux modèles toutes les semaines. Les inférences sont produites quotidiennement et contiennent les prédictions des sept prochains jours. Nous surveillons régulièrement les scores des modèles ainsi que certaines métriques essentielles pour suivre la qualité des prédictions.
L’information voyageurs étant particulièrement sensible, nous avons fixé un seuil minimal de probabilité sur nos prédictions : ainsi, nous affichons uniquement les prédictions que nous jugeons suffisamment fiables.
Le projet est en production sur notre plateforme Big Data Azure depuis l’été 2019, avec une implémentation en Spark Scala. Les prédictions du retard seront bientôt intégrées au calculateur d’itinéraire de l’application SNCF.
L’œil du chef de projet
Prévoir les retards pour mieux organiser ses déplacements.
Prévisions Retards a pour but d’apporter une information supplémentaire aux usagers, concernant les retards potentiels de trains. “Nous voulions intégrer une brique d’intelligence supplémentaire dans le CMI (Calculateur Multimodal d’Itinéraires) qui est l’outil permettant de calculer les itinéraires sur l’application SNCF. L’idée était donc de l’enrichir pour lui apporter plus de valeur, et in fine alimenter l’application SNCF”, indique Alexandre Hattab, chef de projet au sein de la team Data & IoT ITNOVEM.
L’idée est de prédire les retards éventuels sur les 7 jours glissants à venir et d’en informer l’usager préparant son itinéraire. Avec ce type d’information prédictive, l’application SNCF deviendrait ainsi un outil d’aide à la décision. Un service ajouté qui s’inscrit totalement dans les objectifs du programme Mobility As A Service (MaaS).
L’enjeu concerne ainsi l’Information Voyageur au sens large, un grand chantier pour SNCF (comme le programme INFO FIRST en atteste). “Nous souhaitons éviter la désintermédiation avec le recours à d’autres applications comme CityMapper ou Moovit par exemple. En tant que service public, nous souhaitons développer nos propres solutions”, détaille Alexandre Hattab.
Pour ce projet, les Data Scientists ont pu valoriser les données historiques sur les circulations des trains, combinées avec d’autres datas (condition météo, calendrier d’événements – voir ci-après), pour aboutir à un modèle algorithmique puissant. Prévisions Retards est le premier projet de machine learning sur les technologies Azure (Microsoft), intégrées dans le cloud et développées par la team Data & IoT.

À propos de l'auteur de cet article
« Après une classe préparatoire MP (Maths-Physique) et une école d’ingénieur, Soumaya Ihihi a rejoint le pôle Data IoT ITNOVEM de e.SNCF en tant que Data Scientist. »


