La Data Science et l’Intelligence Artificielle au service de l’exploitation industrielle des données
Avec plus de 30 000 kilomètres de voies, 15 000 trains transportant 5 millions de voyageurs par jour et 141 000 agents (qui préparent, opèrent les circulations, surveillent et maintiennent le matériel) SNCF dispose d’un patrimoine très riche de données en lien avec ses assets industriels, ses opérations et sa mobilité. Grâce aux capteurs IoT, aux drones ou encore au jumeau numérique, de nouvelles sources de données enrichissent ce patrimoine historique.
Publié le
Par La Redaction
Vers une utilisation plus industrialisée des données
Les données du Groupe SNCF représentent un véritable levier de performance opérationnelle, mais elles restent encore parfois silotées et ne sont que partiellement utilisées par les métiers : leur valeur n’est donc pas exploitée de façon optimale. Pourtant, la clé stratégique pour être plus performant et proposer de nouveaux services innovants et donc, rester un acteur majeur de la mobilité, réside précisément dans une utilisation plus industrialisée des données.
Cette industrialisation suppose une utilisation plus avancée et plus exhaustive des données ainsi qu’un croisement d’informations entre les activités. Aussi, elle repose sur des technologies IT, des outils de Data Science et d’Intelligence Artificielle robustes et performants.
Collecter, stocker, traiter, enrichir et restituer la donnée pour profiter de sa valeur ajoutée
Pour assurer la remontée de flux de données vers une plateforme de stockage, un socle IT robuste doit être mis en place. L’accroissement du volume de données nécessite de prévoir une scalabilité du stockage : c’est la notion de Datalake. Il doit pouvoir croître sans remettre en question le socle IT. Le Datalake doit également présenter des espaces cloisonnés en réponse aux exigences réglementaires de gouvernance et de sécurité, et être intégré au SI pour faciliter les échanges avec la DSI et l’entreprise dans sa globalité.
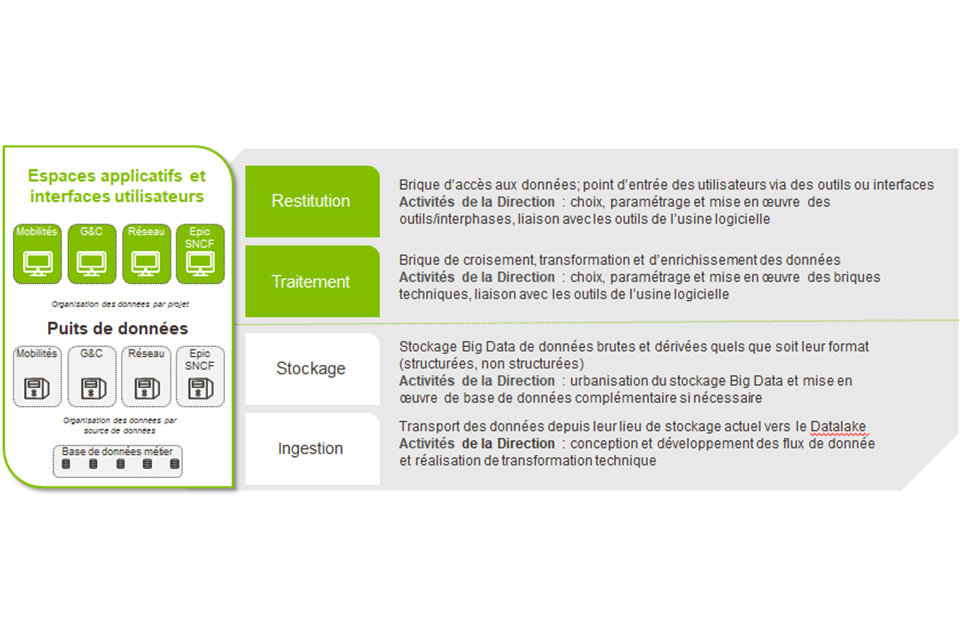
La plateforme Big Data du groupe SNCF est hébergée sur le cloud public de Microsoft, et utilise les services Azure. Au sein de SNCF, le Datalake est cloisonné par Société Anonyme. À titre d’exemple, les données relatives à la consommation d’énergie du matériel roulant sont stockées dans le puits de données réservé à SNCF Voyageurs, tandis que les données relatives à la surveillance du réseau sont quant à elles stockées dans le puits de données réservé à SNCF Réseau. Au-delà du stockage, le socle technologique doit permettre d’opérer les traitements des données tel que le nettoyage, le croisement et l’enrichissement par d’autres sources de données. Par ailleurs, celui-ci doit aussi permettre des traitements plus avancés permettant de produire des analyses et des résultats au service de la prise de décision opérationnelle des métiers, avec par exemple, des algorithmes d’intelligence artificielle. Pour terminer, le socle doit également permettre la mise à disposition -auprès des utilisateurs- des données enrichies ou des résultats des traitements agrégés, via des API ou des bases de données requêtables.
Projet OME : un exemple d’exploitation industrielle des données efficace
Le projet OME (Outil de Management de l’Energie), mené par les équipes Big Data pour la Direction de l’Energie, a pour objectif de calculer la consommation d’énergie des engins moteurs.
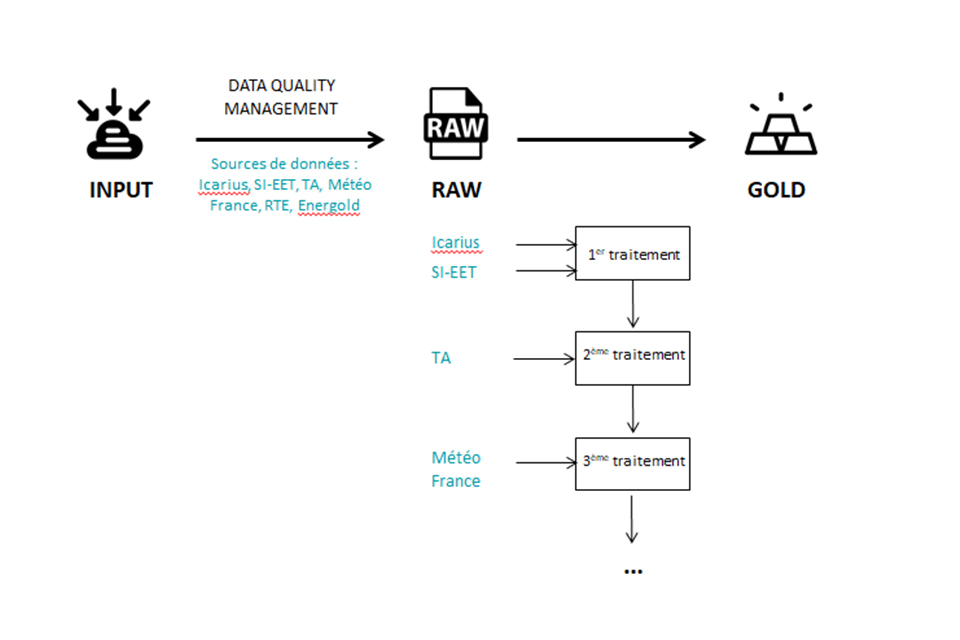
Ce projet intègre six sources de données, dont cinq d’entre elles sont stockées dans le puits de données SNCF Voyageurs. La dernière source – les données météo -, provient quant à elle du puits de donnée SA SNCF.
Les répertoires des sources de données sont scannés chaque soir, à la recherche de nouvelles publications. Ces nouvelles données, stockées dans un dossier nommé « Input » au sein du Datalake, sont ensuite soumises à un traitement de mise en qualité, appelé Data Quality Management (DQM). La DQM vise à contrôler la qualité, la cohérence et la pertinence des données, pour bénéficier in fine de données propres et précises, dont l’utilisation sera efficace.
Dans le cas du projet OME, les équipes Data effectuent des contrôles techniques sur les données (bon formatage d’un champ « date » par exemple), et non des vérifications qui relèvent de l’interprétation métier (l’heure d’arrivée d’un train est postérieure à l’heure de départ, etc.). Mises en qualité, ces données peuvent alors être enrichies grâce aux traitements développés par les Data Engineers de l’équipe Big Data. Ces traitements consistent à décrire la consommation énergétique de chaque train toutes les cinq minutes. Les données enrichies sont alors hébergées dans le dossier « Raw » du Datalake.
Une fois enrichies, ces données sont finalement stockées dans le dossier « Gold » sur le Datalake, puis agrégées dans des tableaux de bord avec l’outil Qlik Sense et enfin mises à disposition du client et des Directeurs Administratifs Financiers (DAF) des différents transporteurs (TER Aquitaine, TGV Atlantique, par exemple).
Enfin, un traitement fonctionnel est exécuté par le métier, au moyen d’une IHM (Interface Homme-Machine), à savoir une interface qui permet à un utilisateur d’interagir avec une machine.
Les données étant un asset aussi précieux que sensible, assurer leur confidentialité est un objectif majeur pour nos équipes ; ainsi, seule l’IHM peut déclencher les traitements des données du projet OME, et seul QlikSense est autorisé à lire les données du projet dans le Datalake.
Un bon exemple des possibilités qu’offrent ces technologies, qui s’inscrivent dans la stratégie Data de SNCF, vitale pour sa transformation numérique.

À propos de l'auteur de cet article
Ingénieur de l’école Centrale de Nantes et diplômé d’un master de Mathématiques de l’université du Chili, Romain Gouron est Data Engineer à la Fab Big Data depuis février 2018.
Crédit photo de couverture Luke Chesser on Unsplash