Projet Napoli : accélérer l’apprentissage des algorithmes grâce à l’Active Learning
L’équipe Data Science et Engineering du pôle IA, Data et IoT ITNOVEM conduit plusieurs projets de recherche et développement sur des thématiques Intelligence Artificielle (IA) et Data jugées utiles pour SNCF. Cette publication vise à présenter l’un d’entre eux : le projet Napoli, applicable à plusieurs cas d’usages pour le Groupe.
Publié le
Par La Redaction

Napoli est un outil d’Active Learning qui accélère l’apprentissage des algorithmes de Machine Learning sur des cas métier complexes, et qui peut s’appliquer aux domaines du Natural Language Processing (analyse du langage naturel), de la Computer Vision (vidéo intelligente), ou à des champs plus classiques du Machine Learning (ML).
Intelligence Artificielle, Data et Internet of Things
anciennement Direction Data IoT du Digital, e.SNCF*
L’active learning : une réponse aux enjeux de SNCF pour faire apprendre efficacement aux algorithmes
De nombreux métiers SNCF souhaitent aujourd’hui inclure le Machine Learning dans leurs processus car les algorithmes d’IA sont performants et permettent de traiter des données en masse. En effet, les algorithmes (ou modèles) de Machine Learning ont un très fort potentiel : s’ils sont bien entraînés, ils se révèlent performants dans leur capacité à prédire ou à prescrire.
Mais, dans des contextes industriels qui intègrent des fortes composantes de sécurité d’une part, et des processus lourds et coûteux comme la surveillance et la maintenance des assets industriels d’autre part, inclure le Machine Learning dans les processus métiers s’avère particulièrement difficile. Ainsi, les cas d’usage industriels (similaires à ceux du Groupe SNCF), contrairement aux cas d’usage marketing par exemple, sont confrontés à de nombreux freins :
Les données liées aux processus métier sont relativement peu nombreuses. Les éléments ciblés sont généralement assez rares (incidents, événements de sécurité, retards, ou fraudes par exemple), et ne représentent qu’une très faible proportion des données à disposition pour entraîner l’algorithme. On parle alors de « données déséquilibrées ». Les données collectées appartiennent à des systèmes d’information qui n’ont pas été conçus pour l’IA. Elles sont donc très souvent structurées et qualifiées pour des processus métier précis. A l’inverse, les données « non structurées » (texte libre, image, etc.) sont relativement peu présentes. Or, ce sont elles qui représentent l’information la plus riche et la plus utile pour entraîner un algorithme de Machine Learning. En plus d’être non structurées, les données industrielles sont très souvent non labellisées (on dit aussi classifiées), à savoir non caractérisées selon le cas d’usage. Malheureusement, les experts capables de les labelliser n’ont que peu de disponibilité. Or, la labellisation des données est un prérequis pour entraîner un algorithme à classifier des documents ou à prédire un événement. En effet, l’apprentissage de l’algorithme est proche de celui d’un être humain : il doit tester, faire des erreurs, et les corriger pour pouvoir « monter en compétences ». Et pour cela, il a besoin de nombreuses données labellisées : on parle alors « d’apprentissage supervisé ».
Les exigences de sécurité industrielle et la nature complexe des processus métier exigent que les algorithmes soient les plus performants possible, avec un nombre d’erreurs très réduit. A titre d’exemple, si SNCF veut prédire une panne critique sur une porte de TGV avec du Machine Learning, la marge d’erreur se doit impérativement d’être faible. Cette exigence est pourtant en complète opposition avec les caractéristiques de nos données d’entrée : non structurées et non labellisées.
Le projet Napoli est mené pour répondre précisément à ces problématiques. En offrant un framework d’Active Learning permettant de produire des modèles de Machine Learning plus performants avec moins de labels, il permet d’accélérer l’apprentissage des algorithmes sur des cas métier complexes.
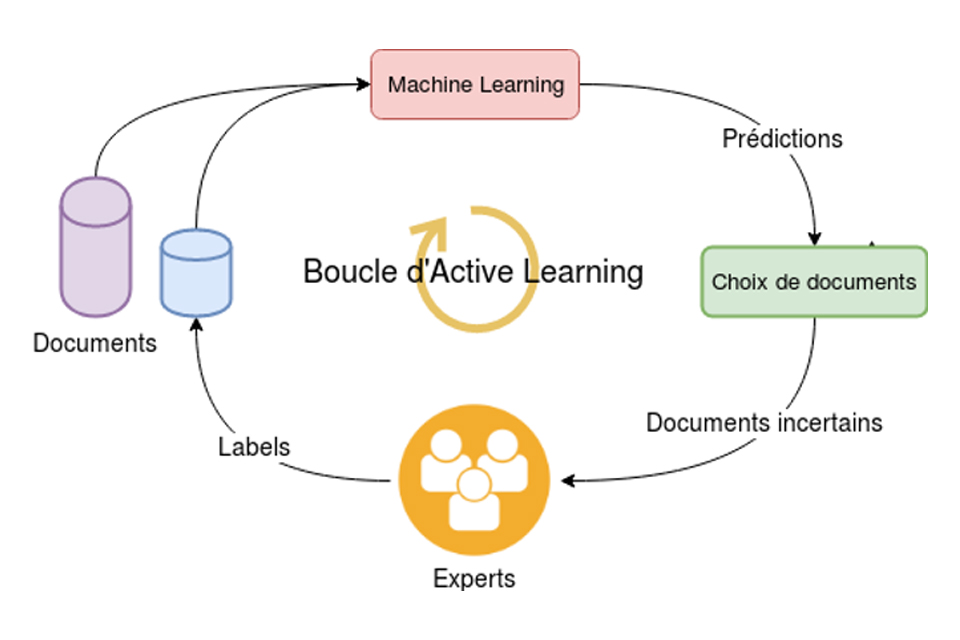
L’Active Learning est un processus itératif : le but est d’améliorer rapidement un modèle jusqu’à ce qu’il soit jugé assez performant pour être mis en production. La procédure débute par la labellisation manuelle d’un petit nombre de documents sélectionnés au hasard dans la base de données non labellisées. Un premier modèle peut alors être entraîné. Les premières performances sont très faibles, mais les prédictions sur l’ensemble de la base permettent à l’Active Learning de choisir un second lot de documents prioritaires pour la prochaine phase de labellisation. Les experts labellisent ce nouveau lot, qui est alors ajouté à la base d’entraînement. Un nouveau modèle plus performant est entraîné et produit de nouvelles prédictions, et ainsi de suite.
Les équipes Big Data ont développé une interface web à destination des experts pour labelliser les documents sélectionnés. Cet outil permet également aux experts de suivre la performance du modèle de Machine Learning et de surveiller ses prédictions, afin de pouvoir corriger ses erreurs d’une part, et de continuer à superviser son apprentissage avec l’arrivée de nouvelles données, d’autre part. A titre d’exemple, pour une tâche de classification, il est possible de créer une nouvelle classe pour représenter des nouvelles données (un nouveau type de panne ou d’incident par exemple). L’Active Learning portera alors son attention sur cette nouvelle classe pour améliorer la performance du modèle.
Le projet Napoli dispense en partie de solliciter les experts métiers sur la labellisation des données, pour leur offrir la possibilité de se concentrer sur les cas complexes pour lesquels l’IA sera toujours moins performante qu’un humain. L’objectif est de continuer à améliorer le framework, afin d’augmenter ses performances pour répondre toujours plus efficacement aux enjeux métier.
Le projet Napoli : Une efficacité démontrée
L’une des premières étapes du projet Napoli a été de prouver la valeur apportée par l’Active Learning : cette méthode permet-elle réellement de construire de meilleurs modèles ? Des benchmarks sur des bases de données publiques déjà labellisées ont alors été conduits par les équipes Big Data.
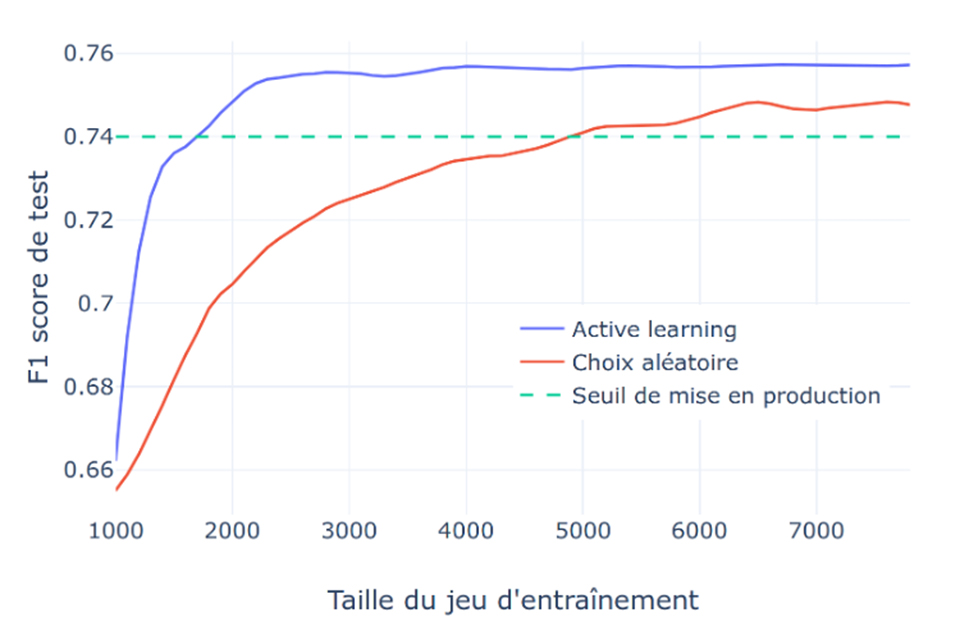
La figure ci-dessous représente les résultats obtenus relativement à une problématique de classification multiclasse de texte (plusieurs types de documents à classifier), sur une base de documents aux classes fortement déséquilibrées. Avec seulement 2 000 documents labellisés, l’Active Learning permet au modèle de quasiment atteindre son plateau de performance, tandis qu’un choix aléatoire ne parvient pas à atteindre les mêmes scores, même avec plus de 6 000 documents labellisés. En fixant un seuil minimal sur le score du modèle (0.74) pour juger de sa mise en production, l’Active Learning permet ici de l’atteindre avec 3 fois moins de labels (1 600 contre 4 800). L’Active Learning parvient donc bien à optimiser la construction de la base d’entraînement pour rapidement créer un modèle performant.
Les cas d’usages SNCF
Le projet Napoli s’applique à des cas d’usages variés au sein du Groupe SNCF. Il a été testé pour classifier des commentaires d’incidents rédigés en texte libre par les agents SNCF -via la base Bréhat Incidents-, et est déjà applicable à un ensemble plus large de cas d’usage de classification de texte.
Napoli pourra également être adapté à d’autres cas d’usage qui nécessitent une labellisation au cas par cas par des experts : détection de défauts sur des images, d’anomalies sur des courbes de charge, ou encore la détection et la caractérisation de bruits. Enfin, d’autres axes innovants sur le sujet sont encore à explorer. Grâce à Napoli, il est possible de mettre en évidence des incohérences ou des ambigüités sur les labels de documents difficiles à classifier. Dans ce cadre, la perspective d’une mise en qualité de bases de données mal labellisées est réelle et structurante pour la stratégie Data du Groupe.
A propos des auteurs de cet article

Paul Soulé est Data Scientist Expert. Il est ancien élève de l’École Normale Supérieure de Lyon et docteur en Physique Théorique de l’Université Paris 11. Il a ensuite travaillé 1 an sur la détection d’anomalies dans les systèmes embarqués, puis a rejoint ITNOVEM en 2016 pour développer l’expertise IA du Groupe SNCF. Paul a notamment été lead data scientist sur un programme autour du MaaS, visant à mieux connaître la mobilité, grâce à des approches algorithmiques sur des données géolocalisées de l’application mobile SNCF.

Après des études en physiques et en géologie à l’Université de Strasbourg, Héloïse Nonne effectue une thèse en physique quantique à Cergy Pontoise. Elle dirige désormais les activités de data sciences à la Direction Data IoT chez e.SNCF.


