De l’IA chez SNCF Voyageurs pour compter les passagers
Le pôle Innovation & Recherche de SNCF met au point un algorithme pour améliorer le comptage automatique des passagers dans les rames Transilien SNCF équipées. Objectif : avoir une vision globale et fiable de la charge de passagers sur le réseau, pour ajuster le trafic en conséquence. Un défi pour l’intelligence artificielle (IA) que raconte Tom Rousseau, chef de projet au Plateau Intelligence Artificielle chez Innovation & Recherche.
Publié le
Par La Redaction

Au premier abord, le sujet paraît simple : il faut compter les passagers présents à bord des trains Transilien SNCF, et ce à chaque gare de la ligne afin d’avoir une vision précise du trafic. Mais plusieurs défis rendent la tâche difficile. Il existe bien des voitures équipées de détecteurs aux portes pour dénombrer les passagers montant et descendant du train, mais elles ne couvrent pas tout le réseau. Et il arrive que la détection de certaines entrées et sorties ne se fasse pas correctement, en cas de présence de bagages, vélos, ou animaux de compagnie par exemple. Il arrive également que les comptages d’une rame soient corrompus, perdus ou incohérents avec le plan de transport, qui est ponctuellement révisé pour absorber d’éventuelles perturbations de trafic. Résultat, lorsqu’on la calcule avec la donnée de comptage brute, la charge de passagers embarqués peut comporter des erreurs importantes (par exemple des trains qui semblent embarquer un nombre négatif de passagers, de nombreux passagers encore à bord au terminus…). La donnée brute doit donc être retravaillée pour corriger les problèmes de mesures et compenser les pertes de données.
Un objectif de comptage en temps réel
Il est possible de retravailler ces données de comptage et de les croiser avec d’autres sources pour obtenir un chiffre plus précis et fiable a posteriori, soit quelques jours après, mais il est bien plus intéressant de chercher à avoir ces données en temps réel, par exemple pour, à terme, mieux répartir les voyageurs dans les voitures. Et c’est là qu’intervient le travail de Tom Rousseau, chef de projet au Plateau IA du pôle Innovation & Recherche chez SNCF.
« La stratégie de mise en qualité que nous avons adoptée se décompose en deux étapes : d’abord, prédire les comptages pour anticiper les éventuelles pertes de données, puis redresser tous les comptages (réels et prédits). En 2020, mon principal défi a été de concevoir un algorithme de redressement des données en temps réel en imitant le système actuellement en vigueur, qui ne fonctionne qu’en temps différé (à J+2/3). En 2021, j’ai pu développer un algorithme complémentaire, visant à prédire les comptages et à compenser les carences de données. En agrégeant les comptages traités par ces deux briques, on obtient une charge de passagers embarqués plus fiable que d’origine » explique-t-il.
Pour prédire la charge de passagers à bord des trains circulant sur le réseau opéré par Transilien SNCF, il faut d’abord avoir des données propres à traiter, c’est-à-dire des données présentées d’une façon standardisée, dépourvues de toute ambiguïté et dont les biais de mesure ont été corrigés. Bien avant de pouvoir nourrir un algorithme, les données de montée/descente, initialement exprimées dans le référentiel de Bombardier (leur producteur), doivent être transposées au référentiel SNCF via une table de conversion, les normes des deux entreprises n’étant pas forcément les mêmes. Pour identifier les éventuelles pertes d’informations, il faut ensuite mettre ces données en correspondance avec le plan de transport de Transilien SNCF, qui possède une architecture complexe, et qui est amené à changer lors d’un incident d’exploitation ou de perturbation majeure de trafic, une difficulté supplémentaire pour le temps réel.
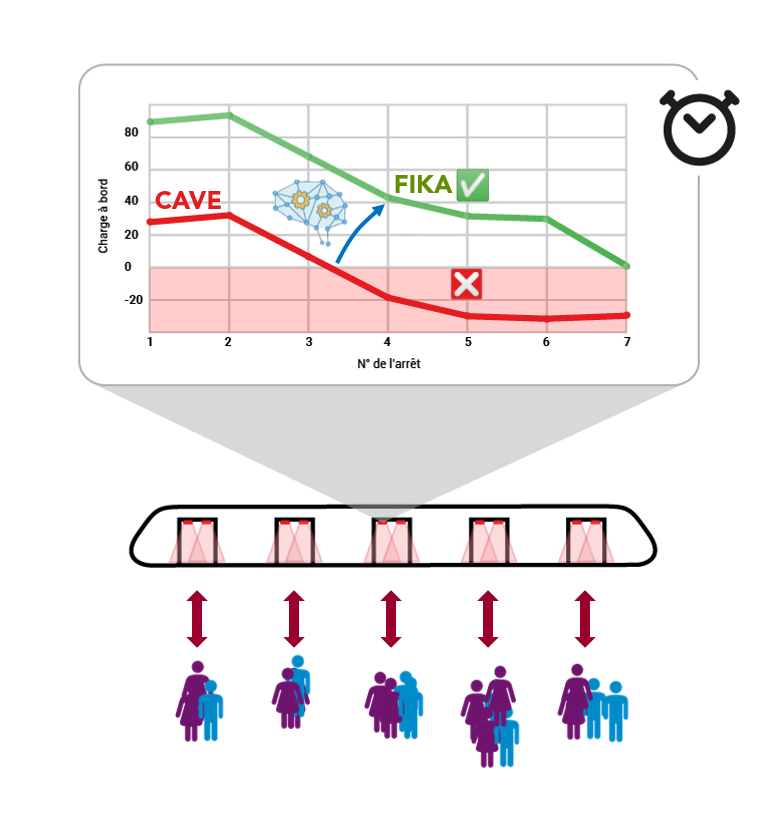
Une collaboration interne et externe
En bout de course, Tom Rousseau conçoit un outil d’IA capable de modéliser la charge de passagers en temps réel, et de prévoir avec une bonne précision la fréquentation. Cette dernière partie est un défi de taille en période de pandémie, car le Covid, les confinements et le recours massif au télétravail ont changé les habitudes et la demande des voyageurs, alors qu’un modèle d’intelligence artificielle apprend les comportements en s’appuyant sur des données passées, majoritairement pré-COVID ici. Un ré-entraînement régulier sur des données plus récentes réduit considérablement le risque d’obsolescence de ces modèles d’apprentissage. C’est la stratégie d’entretien qui a été recommandée à Transilien pour maintenir l’outil à jour.
Cet outil d’IA – nommé FIKA – n’existe pas seul. D’autres sont en cours de conception en interne comme en externe, notamment dans le cadre du projet AIfluence, réalisé en collaboration avec l’ENS-Paris-Saclay et la région Île-de-France, afin de prédire l’affluence dans les gares et les trains sur l’intégralité du réseau d’Île-de-France. Tout cela montre que derrière une question d’apparence simple, « combien de voyageurs y a-t-il sur cette ligne ? », se cache une complexité typique du monde des données.
Crédit photo couverture : Valerie Archeno


